
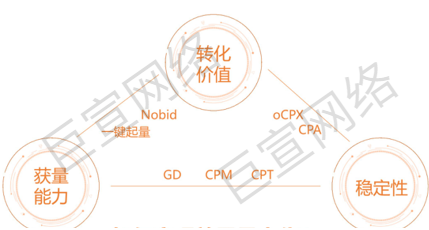
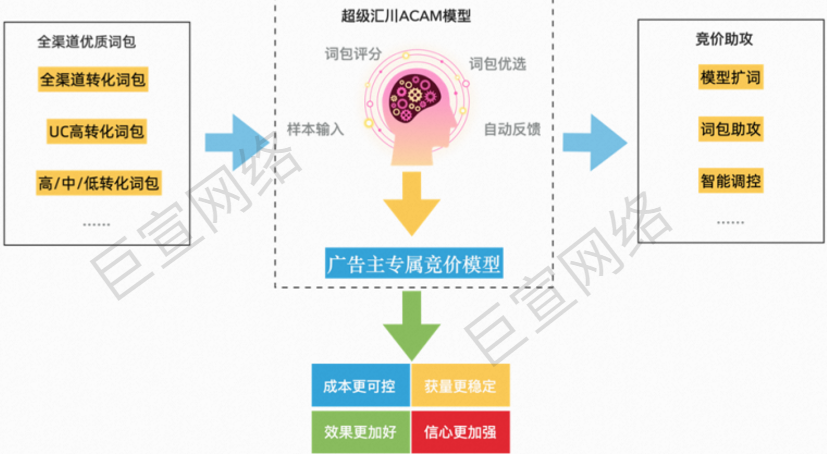
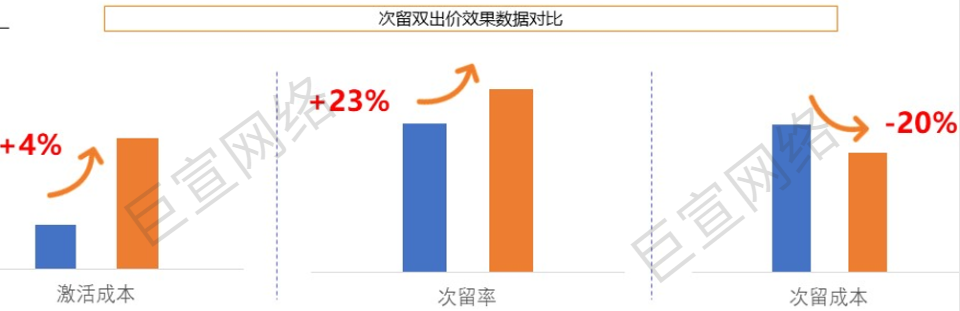







AIGC 的迅猛发展,使AI广告图像生成成为可能。相较传统的画图过程,AI作图更为高效,在节约成本的同时,可以大幅提UC广告图的多样性。
目前市面上大部分图像生成模型都是基于 diffusion 技术,开源的代表作是 stable diffusion 模型。SD模型凭借其出片速度快、画质精美,深受广大创作者的喜爱,而因其生成未本地化、可控性/稳定性不佳等原因,同产品化仍有距离。
我们的工作内容主要是,以扩散模型为核心生成引擎,整合多种技术组装成图像生成的流水线,确保产出高品质、可直接用于投放的UC广告图像。

一、思路设计
AI制图的出现几乎颠覆了原有的制图技术,影响了众多插画师、原画师、设计师的发展方向。AIGC的特点是高效、自动化,但缺少人工干预,生成的效果难以把控。
我们在研究和学习了传统的制图工艺技术后,提出了AI制图的生产流程,主要包括两个阶段:自动制图、质量筛选。

1. 批量生成
其中,自动制图以 Stable Diffusion 模型的生成能力为核心,主要由三部分组成:① 图像前处理 ②训练扩散模型 ③搭建出图流程
前置组件
首先,根据输入的文案要求,映射到不同生产流水线,构建后续的任务队列和调度过程。
其次,解析、筛选、泛化提示词,确保生成内容在模型支持的范围内。
最后,解析好的提示词及其他输入(如有,例如图片、视频等)写入生成队列,等待生成。
扩散模型
扩散模型是生成能力的发动机,通过对模型的训练、改造,可以增强其生成能力。对模型的影响主要包括:①数据训练 ②模型改造两种方式
数据训练
通过收集图像、prompt pair 对,来增强模型在特定数据领域的能力,如:收集场景类图文对,生成更本土化的场景类图像(乡村、街道、健身房等)
模型改造
- 微调网络结构,如:dreambooth 微调网络,学习电商实体,推理阶段可通过 prompt 控制产出多种风格的电商产品图像
- 增加子网络,如:lora 学习子网络,学习人物实体,推理阶段可通过 prompt 控制产出不同发式、衣着、姿态、场景 的人物图像
后置组件
图像生成好了,还需围绕模型产出搭建后处理流程,以补足模型的能力,提高出图率。模型后置组件主要包括以下几种:
二次处理:对已有的图像进行元素组合、画风变换、背景变换等.
图像裁剪:调整图像尺寸,以适应不同业务场景的需要。
要素编辑:对已有图片进行文字编辑、增加logo、水印等工作。
2. 质量筛选
尽管模型已经做过定制化的优化训练,其出图的成功率仍然较低,因此需要对于批量产出的图片素材进行质量筛选,目前主要是人工筛选,后续规划会有三个阶段。
模型初筛:应用通用风险模型,目标检测模型等检测图像问题。
图像优化:使用商业价值模型评估图像质量,获取商业价值较高的图像集合优先使用。
人工抽审:应用审核、物料标注人力来对最终集合进行复审、抽审,以确保图像的可用性。
二、技术方案
目前在建的制图流程主要有三大类:人物类流程、UC广告底图流程和意向图文类流程。在各类图片的生成流程中,人物类图片的需求最多,挑战也最大,因此其制图流程也最复杂。
此后,重点以“人物生成”为例,说明制图流程的操作过程,并介绍涉及的多种技术的运用方法。
1. 制图流程介绍
各类制图技术的流程示意图如下:
人物类流程:当前主要实现在人脸 ID、发式、服饰、表情、体态、背景等维度上的可控。

UC广告底图类流程:根据具体的广告营销业务点,应用大语言模型的创意提供能力、综合历史上的高价值物料,整理高质量 prompt,应用 stable diffusion 生成能力,生成多样化的广告底图。

意向图文类流程:在UC广告营销领域,“意向”的借用,配以和业务点相关的“宣传语”,往往能起到直击人心的营销效果。在“意向”、“宣传语”的获取方面,我们依然以大语言模型、历史高价值物料为依据;在文字渲染方面,既可用传统的选取特定字体、字号、颜色的渲染方式,也可直接应用模型(deepfloyd IF)的添加文本方式,前者可控性更强,而后者和图像的整体融合度更自然,可据具体情况选用。

2. 人物制图过程
获取人脸素材-GAN
GAN是一种生成对抗网络模型,基于GAN技术,可以生成丰富的包括不同性别、年龄段、特点的人脸。它的生成器是一个深度卷积神经网络,它由多个层组成,每个层都包含一组卷积和上采样操作,用于将中间向量转换为图像。
生成的步骤如下:
首先,GAN 利用了一组预训练的人脸图像数据集进行训练,学习人脸的特征和风格。
然后,在训练过程中,GAN 将潜在空间向量与可训练的转换器结合,以生成具有不同特征和风格的中间向量,形成(向量、风格)pair对。
最后,将这些中间向量输入到生成器中,就可以获得逼真的人脸图像。
此外,为了避免生成的人脸图像出现棕色或灰色调,GAN 还引入了一个归一化操作,用于平衡不同层之间的输出。GAN 还引入了一种新的技术,称为“progressive growing”,它可以在训练过程中逐渐增加图像的分辨率,从而产生更高质量的图像。最终,GAN 可以生成高度逼真、多样化和可塑性的人脸图像。

控制人物发式、服饰
人物的发式、服饰控制基于StableDiffusion + lora实现的。LoRA,英文全称 Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,是微软的研究人员为了解决大语言模型微调而开发的一项技术,使其它用在cross-attention layers(交叉关注层)也能影响用文字生成图片的效果。它对人脸的学习效果介于 dreambooth、texual inversion 两者之间,参数文件大小可控:2-200 MB,对人物的发式、服饰泛化生成能力极佳。
交叉注意力层的权重以矩阵形式排列, LoRA模型通过将不同的权重添加到这些矩阵中来微调模型。LoRA 模型文件可以做到很小的的技巧是:将矩阵分解为两个较小的(低秩)矩阵,通过这样做,则可存储更少的参数。

各类文档中往往标示出需要至少3张相同的人脸图像来进行学习,经实验,如对面部无多角度生成需求(如广告图大多数人物形象为正面照),仅用一张人脸图像学习即可(需要为清晰正面照)。
& 生成人物示意图")
编辑人物表情、体态
在表情方面,我们参考了高价值广告图中的人物表情,用于后期的表情迁移,目的在于明确传达广告图中人物遇到问题时的“苦闷”及解决问题后的“喜悦”情绪;表情迁移技术当前比较稳定的方案是 controlnet 的面部控制。
在体态方案,参考高价值广告图中的人物体态特征:分别用 blender、openpose 生成提取人物姿势;应用 depth 模型提取人物综合体态特征图(即深度图),相较于姿势图,深度图能同时刻画“姿势+身材”;然后用 sd + controlnet 实现,controlnet 作为 sd 的补充网络,生成过程分为两个阶段:
首先,用预处理模型提取人物表情、姿势、深度图
其次,应用 controlnet 大模型作用于 sd 网络,控制按指定表情、姿势进行人物生成。

调整人物背景
针对UC广告主营销业务特点,让人物出现在恰当的场景里,如小说类图像人物出现在:健身房、客厅、卧室、花店等室内场景,及公园、山谷、海边等户外场景。背景图的自动化生成工作主要有以下步骤:
首先,收集背景图库,图片可由 sd v2.1 直接生成高清图片,经人工筛选可用,只需找到合适的prompt 。
其次,对包含人物的原图进行抠图,用于后续的背景合成,现基于 PaddleMatting 做人物抠图,未来考虑应用 SAM(Segment Anything Model)实现。
最后,按最终输出图像比例,应用 pillow 库 alpha_composite 方法合成至背景图相应位置。
后置处理过程
上述过程完成后,为了在UC广告业务实现更好的营销效果,会在图像中添加广告语、品牌logo、水印等信息;除此之外,部分商品按规定需要在广告图上明确标识出营销产品基本信息。这里,我们应用准备好的广告语,及广告主提供的产品信息,结合人物识别模型,将广告语及产品信息添加至合适的位置上,保证人物不遮挡。至此,一张可以用于线上投放的人物广告图就完成了。
在长期上,我们将不再局限于标签化的图像生成,而是让用户自由地同大语言模型去交互,沟通广告创意,模型会给到用户相关性较大的十几、二十种图文示例,用户从中选择一种,选择"量产"。

- 2024-10-19
uc广告推广利器上新:“差异化素材”扶持策… - 2024-10-19
SDPA广告上线,uc广告智能营销助力“单品模… - 2024-09-25
uc广告营销帮助好创意持续跑量:超级汇川智… - 2024-09-12
uc广告代理商优质内容大放送 | uc广告推广… - 2024-09-06
超级汇川商业化主端平台—uc浏览器广告投放… - 2024-08-29
内容+AI科技+融合创新走进uc广告推广,共探… - 2024-08-22
uc搜索广告共享预算如何操作,对UC广告账户… - 2024-08-14
uc广告平台超级汇川智投版:AIGC功能上新速… - 2024-08-12
在UC投放广告的展示位置在哪里?UC广告的展… - 2024-08-06
如何在UC投放广告?UC广告开户该联系谁?|…
管理员
该内容暂无评论